An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
前言 - 《使用 Luiti 来构建数据仓库》 是关于大数据处理的实战经验总结的系列文章,面向的读者范围是对数据处理有一年以上经验的人。 众所周知, Hadoop 和 新兴的 Spark 是当前最流行的分布式计算和存储平台,但是均和保守死板的 Java 编程语言所绑定。 R 和 SQL 因为专业领域和表达能力的有限性而导致始终不能一统江湖。 而 Python 作为一个通用的脚本语言也拥有一个完全可以与 Java 匹敌的生态环境, 在 Web 开发,机器学习,文本挖掘, 爬虫等方面均有众多优秀的框架和类库。并且 Python 可以作为工业胶水把前述几个技术方案融合成一个相互补充的解决方案。 本系列文章的侧重点在于从 Python 的函数式特征出发,来逐步讲解一个有约定而不失灵活性的离线数据仓库处理框架是怎么来的, 和可以做什么。欢迎关注 http://luiti.github.io 。
先上一个常规软件开发中的层次图:
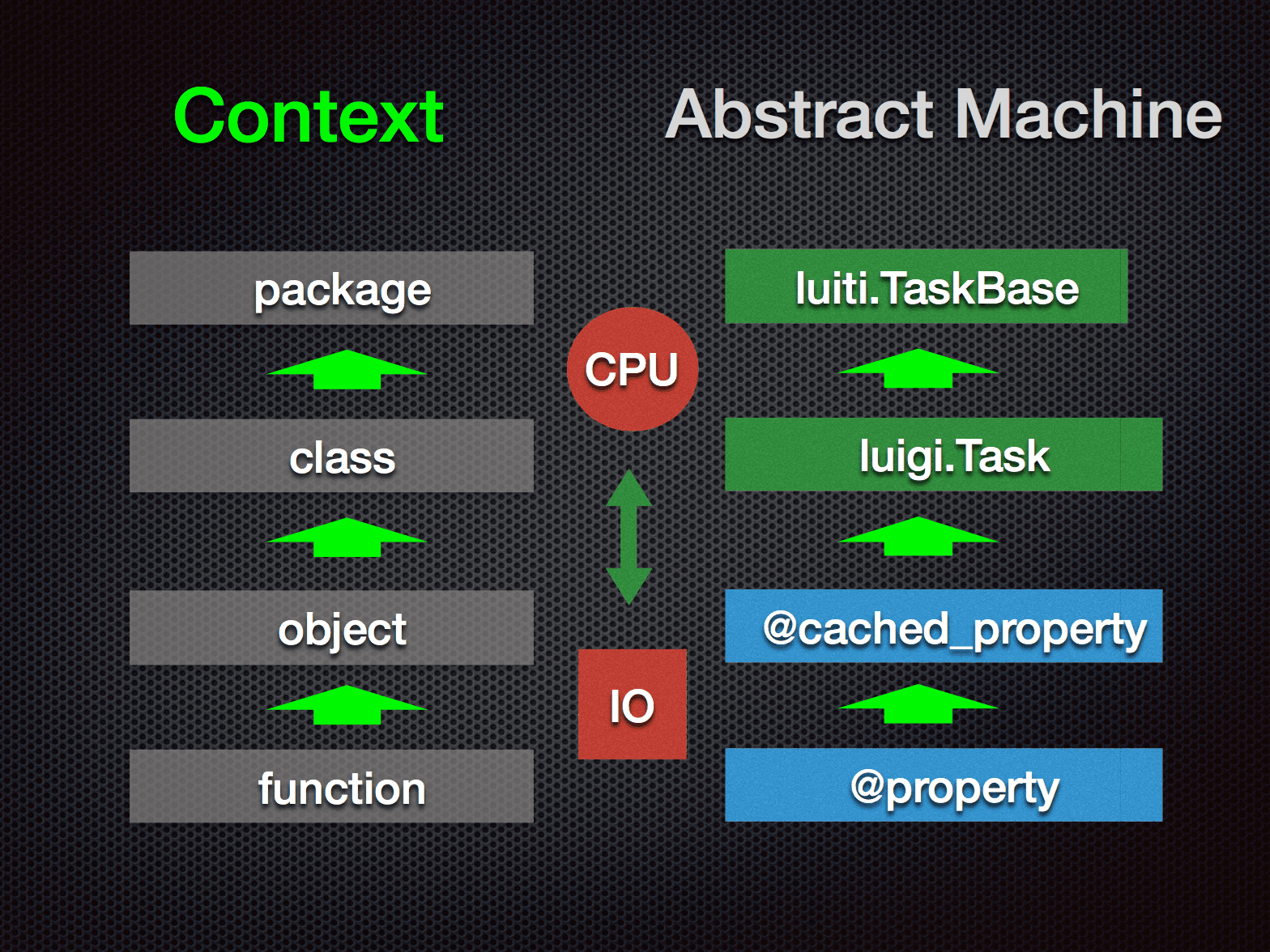
从代码组织的上下文来讲,大概分为 function,object,class,package 四个从局部到整体的抽象层次。
Luigi 是一个 module ,除了在 class 层面上实现的约定外,其功用在于被调用。 而 Luiti 则是一个 framework,从文件目录和命名等外部组织方式上做了强制约束( 虽然内部属性可以被灵活扩展),业务代码必须被放置在固定的位置以备调用。在这一约定下, 一个报表项目,数据分层,业务分块,等都可以被封装到一个相对当时静态的 package 里去。 数据的稳定性在于这个 package 的软件质量和健壮性。从而我们可以建立起一套灵活的流程来保证公司数据良好生产的职能。
再看截图的右边是一系列函数与数据相互映射的机器,它们各自拥有不同的抽象程度,区分如下:
@property 是每次调用均会重新计算的,即是没有缓存的。@cached_property 在第一次计算后,下次访问就会命中缓存的,特点是重启 Python 进程后就丢失了。luigi.Task 的输出文件地址是必须要被手工定义的,同一 Task 的同一参数计算后,
(通常)会缓存结果数据到持久化的磁盘设备上,下次启动 Python 去执行该代码,是可以重新利用这段缓存磁盘数据的。luiti.TaskBase 相对 luigi.Task 来说更加易用一点,不强制配置路径,
因为 luiti 默认会根据任务名称和日期自动推荐一个文件输出地址的。因此,Luiti 让你更专注于 业务的逻辑,而不用太去具体关心数据的存放位置和缓存等非必要的技术细节。 在 Luiti 可视化 里也可以看到, 正是这种约定配置的机制,我们可以很方便的把 处理数据的代码 本身也当作 元数据 来管理起来,在网页里直接导航数据仓库里的数据地址。
注明: 如果不理解 @property 或者 @cached_property 具体作用,请移步
《使用 DAG 来解耦 数据处理中的复杂逻辑》 。