An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
前言 - 《使用 Luiti 来构建数据仓库》 是关于大数据处理的实战经验总结的系列文章,面向的读者范围是对数据处理有一年以上经验的人。 众所周知, Hadoop 和 新兴的 Spark 是当前最流行的分布式计算和存储平台,但是均和保守死板的 Java 编程语言所绑定。 R 和 SQL 因为专业领域和表达能力的有限性而导致始终不能一统江湖。 而 Python 作为一个通用的脚本语言也拥有一个完全可以与 Java 匹敌的生态环境, 在 Web 开发,机器学习,文本挖掘, 爬虫等方面均有众多优秀的框架和类库。并且 Python 可以作为工业胶水把前述几个技术方案融合成一个相互补充的解决方案。 本系列文章的侧重点在于从 Python 的函数式特征出发,来逐步讲解一个有约定而不失灵活性的离线数据仓库处理框架是怎么来的, 和可以做什么。欢迎关注 http://luiti.github.io 。
说明: 以下文档基本翻译自 Luigi 官方 Github 的 README ,以及 官方文档主页 。当前文档更新时间为 20150905 ,更多请访问 https://github.com/spotify/luigi 。
按照 官方介绍 的定义是,Luigi 是一个用来帮助你构建基于复杂管道的批处理任务。 它的功能包括 依赖处理,工作流管理,可视化,等等。它同时也内建支持 Hadoop 。
Luigi is a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built in.
Luigi 的目的是在于把长时间运行的批处理任务通过管道机制关联起来。通常你会串接很多 任务,自动化它们,然后也肯定会发生各种错误。这些任务可以是任何内容,但是通常是一些 像 Hadoop 任务这样长时间运行的,导入或导出数据到数据库,跑一些机器学习算法,或者 其他东西。
The purpose of Luigi is to address all the plumbing typically associated with long-running batch processes. You want to chain many tasks, automate them, and failures will happen. These tasks can be anything, but are typically long running things like Hadoop jobs, dumping data to/from databases, running machine learning algorithms, or anything else.
业界同时也存在其他专注于数据处理的某些底层侧面的的软件包,比如 Hive,Pig,或者 Cascading 。Luigi 不是一个用来替换这些的框架,而是辅助你把许多任务粘合到一起, 这些任务可以是一个 Hive 查询,一个用 Java 写的 Hadoop 任务,一个用 Scala 或者 Python 片段代码写的 Spark 任务,从数据库里导出一个表,或者其他。用 Luigi 很容易 去构建长时间运行的任务管道,其数量可达上千个,运行时间超过天和周去完成。Luigi 已经处理好了大量的工作流管理,这样你可以专注在任务自身和它们的依赖关系上。
There are other software packages that focus on lower level aspects of data processing, like Hive, Pig, or Cascading. Luigi is not a framework to replace these. Instead it helps you stitch many tasks together, where each task can be a Hive query, a Hadoop job in Java, a Spark job in Scala or Python a Python snippet, dumping a table from a database, or anything else. It's easy to build up long-running pipelines that comprise thousands of tasks and take days or weeks to complete. Luigi takes care of a lot of the workflow management so that you can focus on the tasks themselves and their dependencies.
你可以用你想要的方式去构建各种任务,但是 Luigi 也自带了包含很多你常用的任务模版 的工具箱。它包括支持在 Hadoop 里运行 Python 编写的 MapReduce 任务,以及还有 Hive 和 Pig 等。它也自带支持 HDFS 和 本地文件的文件系统抽象,用来确保文件系统操作是 原子的。这是很重要的,因为这意味着你的数据管道不会因为其中一个状态只包括了部分数据 而导致崩溃。
You can build pretty much any task you want, but Luigi also comes with a toolbox of several common task templates that you use. It includes support for running Python mapreduce jobs in Hadoop, as well as Hive, and Pig, jobs. It also comes with file system abstractions for HDFS, and local files that ensures all file system operations are atomic. This is important because it means your data pipeline will not crash in a state containing partial data.
只是想为了给你大概了解 Luigi 到底是做什么的,这里选取了一张我们生产环境里跑的任务的截图。 通过使用 Luigi 的可视化,我们得到了一个漂亮的可视化概览,展现了当前工作流里的整个任务 依赖图。每个节点都表示要被运行的任务。绿色任务表示已经完成了,相对应的是黄色任务表示还未 运行。大部分任务都是 Hadoop 任务,但是有些也是跑在本地的,并且也构建了数据文件。
Just to give you an idea of what Luigi does, this is a screen shot from something we are running in production. Using Luigi's visualizer, we get a nice visual overview of the dependency graph of the workflow. Each node represents a task which has to be run. Green tasks are already completed whereas yellow tasks are yet to be run. Most of these tasks are Hadoop jobs, but there are also some things that run locally and build up data files.
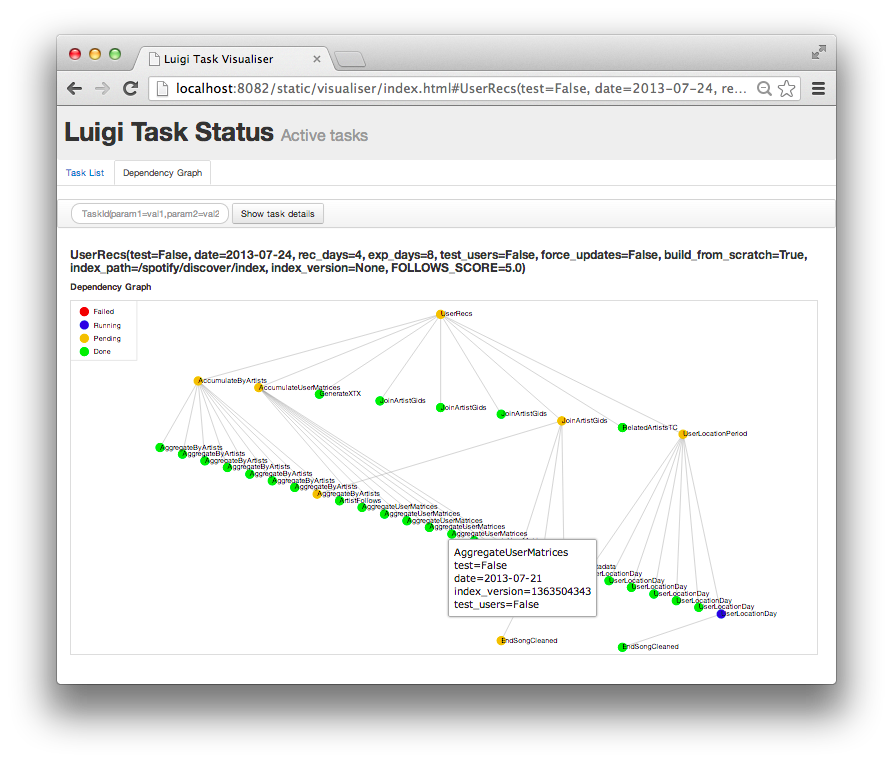
我们在 Spotify 内部使用 Luigi 来每天跑数以千计的任务,它们被组织在复杂的依赖图里。 大部分任务都是 Hadoop 任务。Luigi 提供了一种架构,支撑着像 推荐,排行榜,A/B 测试分析 外部报表,和内部仪表盘等各种任务。Luigi 起源于需要为批处理提供一个强有力的抽象,从而帮助 程序员专注于最重要的点上面,而把剩下的(就是模版)都交给框架去处理。
We use Luigi internally at `Spotify
从概念上讲,Luigi 类似于 GNU Make,比如你有一些任务,而这些任务又依赖其他任务。 这个也和 Oozie 和 Azkaban 有些相像。一个显著的不同在于,Luigi 不是只为了 Hadoop 而构建的,它也很容易扩展到其他类型的任务。
Conceptually, Luigi is similar to `GNU
Make
在 Luigi 里任何东西都是 Python 。它没有采用 XML 配置或者类似的外部数据文件, 而是直接在 Python 里指定依赖图。这样就非常简单去构建起复杂的任务依赖图, 比如涉及到时间代数或者递归引用到当前任务的其他版本(这个正是 Luiti 存在的目的, 译者注)。不管怎样,工作流触发的东西不只是 Python 里的,还包括比如 Pig 脚本, 或者 scp 之类。
Everything in Luigi is in Python. Instead of XML configuration or
similar external data files, the dependency graph is specified *within
Python*. This makes it easy to build up complex dependency graphs of
tasks, where the dependencies can involve date algebra or recursive
references to other versions of the same task. However, the workflow can
trigger things not in Python, such as running
`Pig scripts
以下这些公司写了关于 Luigi 相关的博客或演讲稿:
请访问 Luigi 官方文档 http://luigi.readthedocs.org/en/latest/example_top_artists.html ,里面包括了如下四个部分:
如果想要真正地用好 Luigi ,你还是大概得知道它是怎么回事的。简单的说就是以下五个部分: