An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.

![]()



As Luigi's homepage said, it's "a Python module that helps you build complex pipelines of batch jobs. It handles dependency resolution, workflow management, visualization etc. It also comes with Hadoop support built in."
Luiti is built on top of Luigi, separates all your tasks into multiple
packages, and forces one task per one Python file. Luiti task classes
can be managed by the luiti command, supported operations are ls, new,
generate, info, clean, run, and webui.
Luiti is born to build a layered database warehouse, corresponding to the different packages we just mentioned. A data warehouse consists of synced data sources, fact tables, dimension tables, regular or temporary business reports.
The essence of batching processing system is to separate a large task into small tasks, and the essence of business report is that a daily report or a weekly report is requried, so here comes TaskDay, TaskWeek, and more. Task classes also have a Hadoop version, such as TaskDayHadoop, TaskWeekHadoop, and so on.
You can pass any parameters into Luigi's tasks, but Luiti recommend you
to pass only date_value parameter. So you can run Luiti tasks
periodically, e.g. hourly, daily, weekly, etc. luiti = luigi + time.
Keynote Luiti - An Offline Task Management Framework
After installed package, you can use luiti command tool that contained
in the package.
$ luiti
usage: luiti [-h] {ls,new,generate,info,clean,run,webui} ...
Luiti tasks manager.
optional arguments:
-h, --help show this help message and exit
subcommands:
valid subcommands
{ls,new,generate,info,clean,run,webui}
ls list all current luiti tasks.
new create a new luiti project.
generate generate a new luiti task python file.
info show a detailed task.
clean manage files that outputed by luiti tasks.
run run a luiti task.
webui start a luiti DAG visualiser.
./example_webui_run.py
# or
luiti webui --project-dir your_main_luiti_package_path
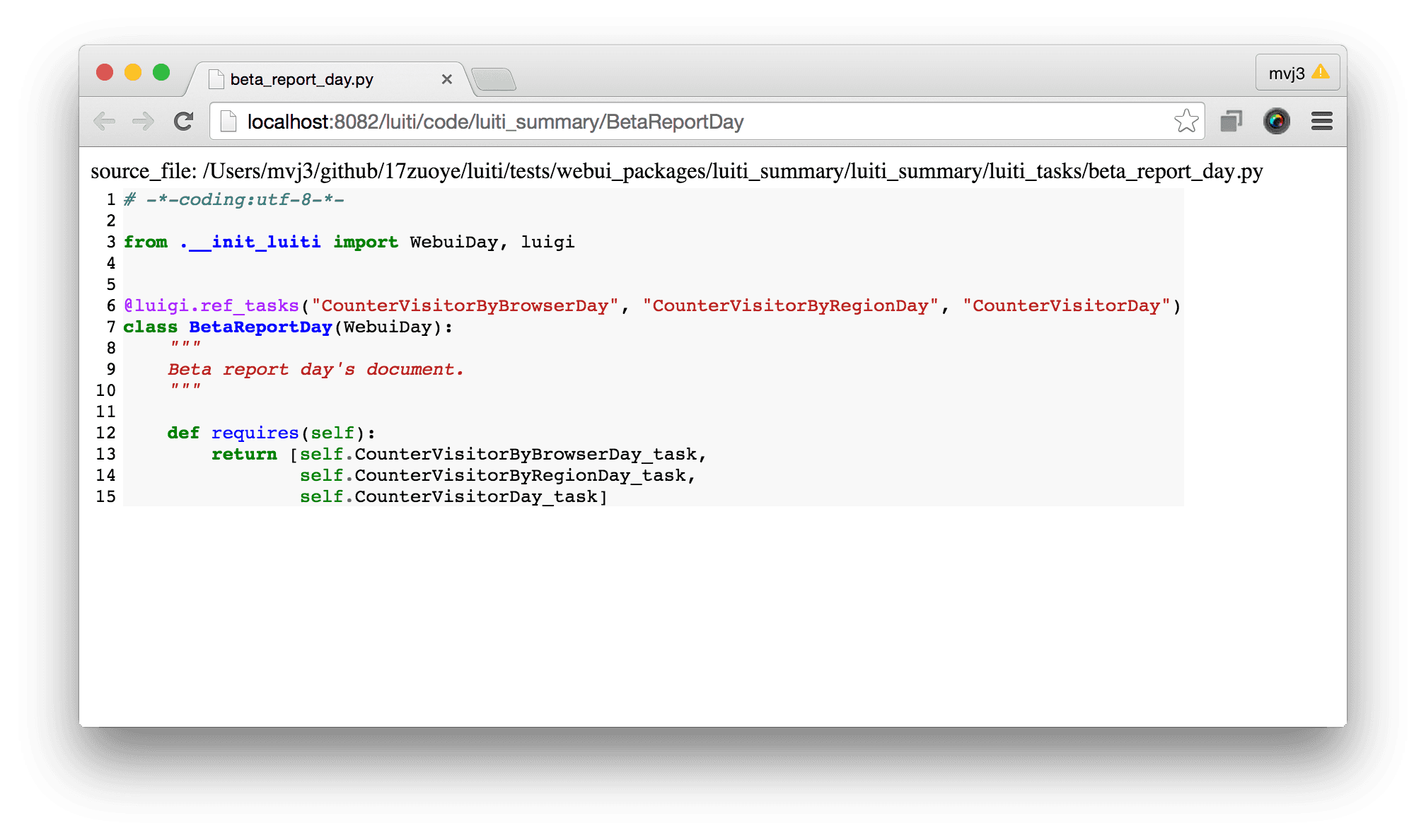
Here's some screenshots from examplewebuirun.py, just to give you an idea of how luiti's multiple Python packages works.
Luiti WebUI list
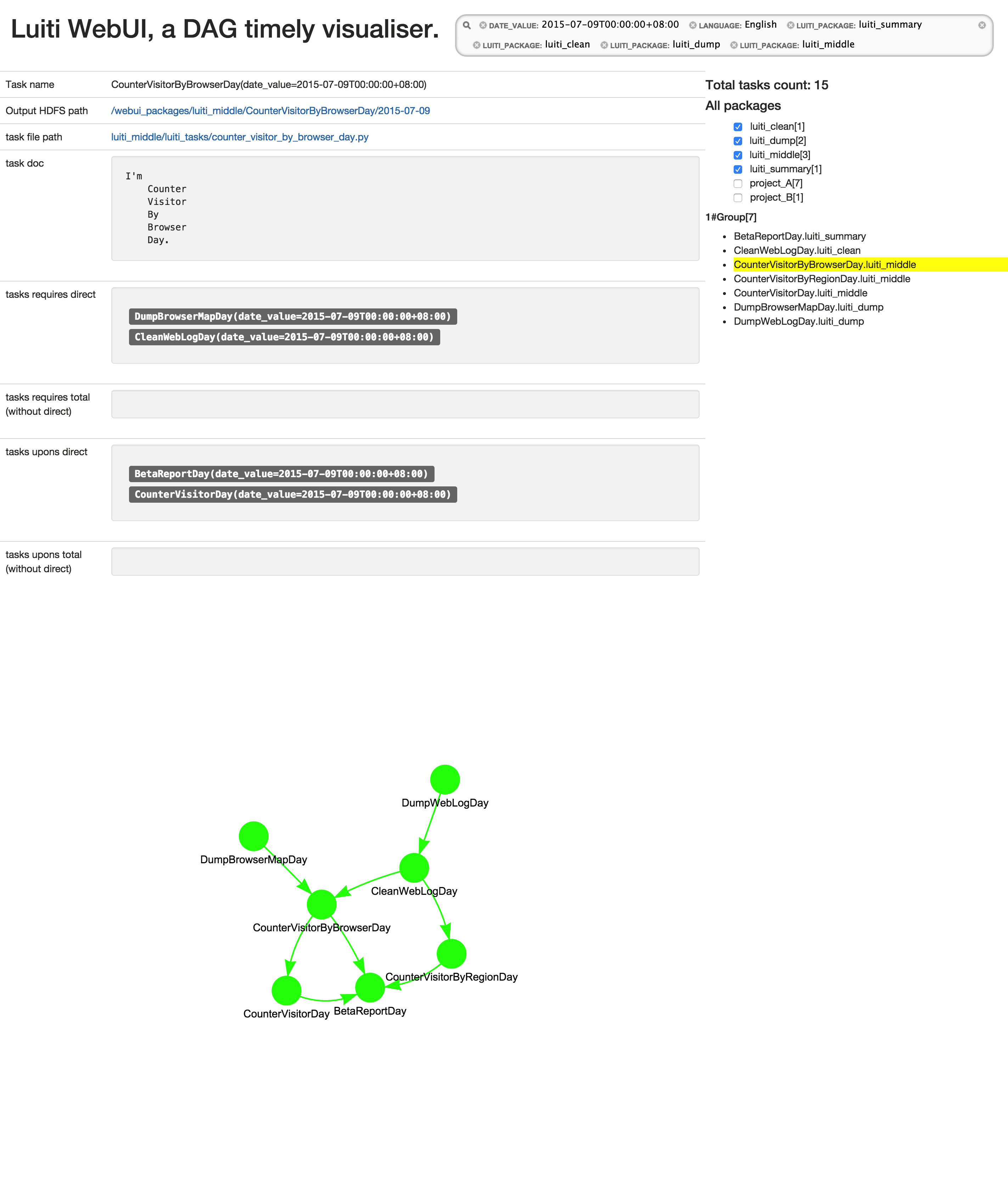
Luiti WebUI show
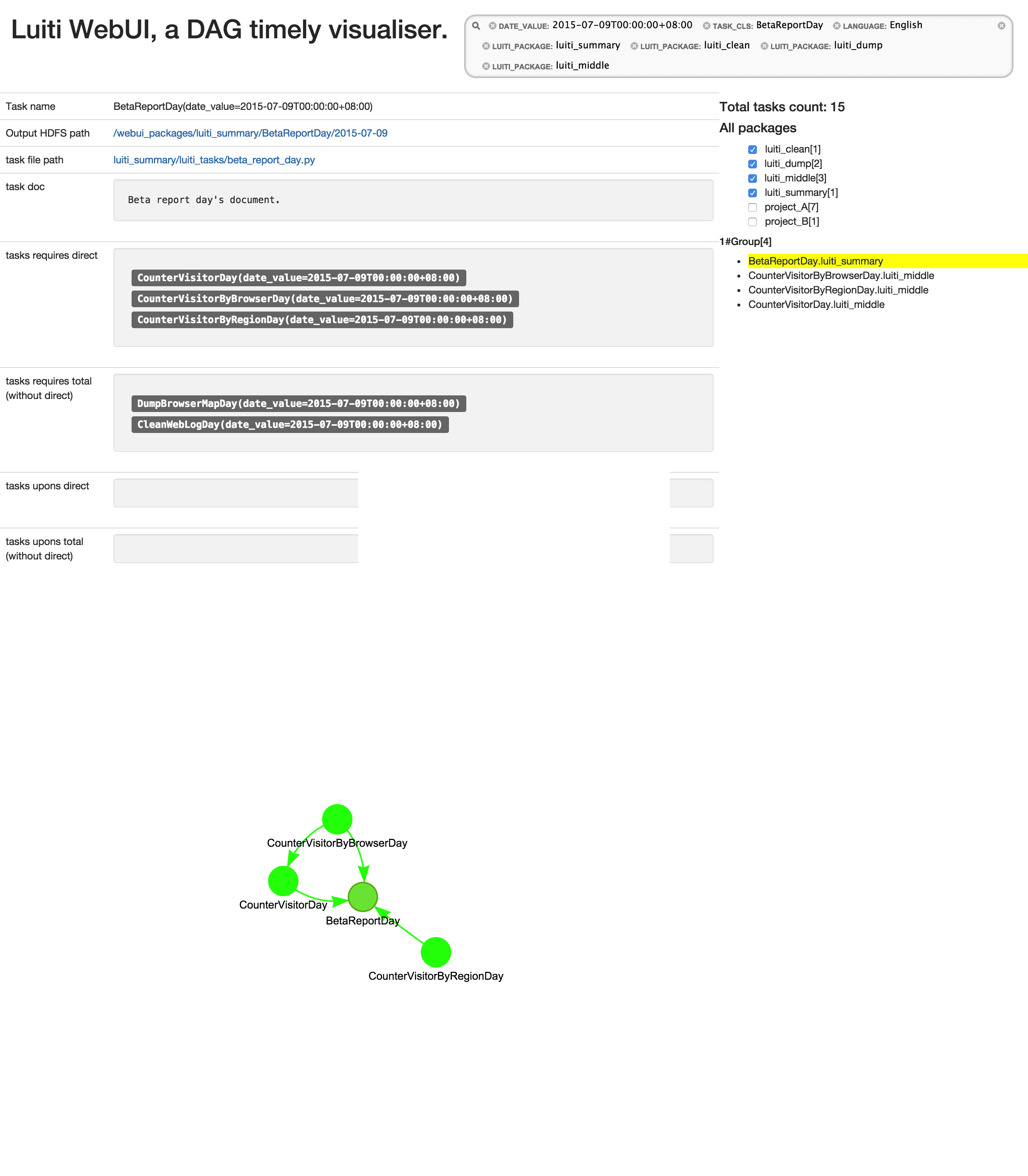
Luiti Code show
You can extend more date type by subclass TaskBase, and make sure the
date types are added in TaskBase.DateTypes too.
EnglishStudentAllExamWeek), file name should be low case with underscore ( e.g. english_student_all_exam_week.py ).luiti_tasks. luiti use this convertion to linking tasks inner and outer of pacakges.TaskBase.DateTypes.date_value. Required, even it's a Range type Task. This ensure that output will be written to a day directory.data_file. The absolute output file path, it's a string format.data_dir. The directory of the absolute output file path, it's a string format.root_dir. The root path of this package. data_file and data_dir are all under it.output. Basic Task's output class is LocalTarget, and Hadoop Task's output class is hdfs.HdfsTarget.date_str. A datetime string, such as "20140901".date_type. A string that generated from task class name, e.g. Day, Week, etc.date_value_by_type_in_last. If current date type is Week, and it'll return the previous week's date_value.date_value_by_type_in_begin. If current date type is Week, and it'll return Monday zero clock in the current week.date_value_by_type_in_end. If current date type is Week, and it'll return Sunday 11:59:59 clock in the current week.pre_task_by_self. Usually it returns previous task in the current date type. If reaches the time boundary of current date type, it returns RootTask.is_reach_the_edge. It's semester at 17zuoye business.instances_by_date_range. Class function, return all task intances list that belongs to current date range.task_class. Return current task class.We recommend you to organize every project's directory structure as the below form, and it means it's also a normal Python package, for example:
project_A --- project directory
setup.py --- Python package install script
README.markdown --- project README
project_A/ --- Python package install directory
├── __init__.py --- mark current directories on disk as a Python package directories
└── luiti_tasks --- a directory name which indicates it contains several luiti tasks
├── __init__.py --- mark current directories on disk as a Python package directories
├── __init_luiti.py --- initialize luiti environment variables
├── exam_logs_english_app_day.py --- an example luiti task
├── ..._day.py --- another example luiti task
└── templates --- some libraries
├── __init__.py
└── ..._template.py
After installing luiti, you can run following command line to generate
a project like above.
bash
luiti new --project-name project_A
If other luiti projects need to using this package, and you need to
install this package, to make sure luiti could find them in the
search path (sys.path) of Python modules.
Every luiti projects share the same structure, e.g.
project_A/luiti_tasks/another_feature_day.py. After config
luigi.plug_packages("project_B", "project_C==0.0.2"]) in
__init_luiti.py, you can use @luigi.ref_tasks("ArtistStreamDay') to
indicate current Task to find ArtistStreamDay Task in current package
project_A, or related project_B, project_C packages.
Luigi's core concept is to force you to separte a big task into many small tasks, and they're linked by atomic Input and Ouput. Luigi contains four parts mainly:
output function, such as LocalTarget and hdfs.HdfsTarget.requires function, and the
function is supposed to return some or None task instances.luigi.Parameter,
e.g. DateParameter, etc.run function if running at local, or mapper and reducer
if running on a distributed MapReduce YARN.After finish the business logic implementation and test cases, You can
submit your task to the luigid background daemon. luigid will
process task dependencies automatically, this is done by checking
output is already exists (It's the Target class's function). And
luigi will guarantee that task instances are uniq in current
luigid background process by the task class name and parameters.
Code below is copied from http://luigi.readthedocs.org/en/latest/exampletopartists.html
import luigi
from collections import defaultdict
class AggregateArtists(luigi.Task):
date_interval = luigi.DateIntervalParameter()
def output(self):
return luigi.LocalTarget("/data/artist_streams_%s.tsv" % self.date_interval)
def requires(self):
return [Streams(date) for date in self.date_interval]
def run(self):
artist_count = defaultdict(int)
for input in self.input():
with input.open('r') as in_file:
for line in in_file:
timestamp, artist, track = line.strip().split()
artist_count[artist] += 1
with self.output().open('w') as out_file:
for artist, count in artist_count.iteritems():
print >> out_file, artist, count
artist_project/luiti_tasks/artist_stream_day.pyfrom luiti import *
class ArtistStreamDay(StaticFile):
@cached_property
def filepath(self):
return TargetUtils.hdfs("/tmp/streams_%s.tsv" % self.date_str
artist_project/luiti_tasks/aggregate_artists_week.pyfrom luiti import *
@luigi.ref_tasks("ArtistStreamDay')
class AggregateArtistsWeek(TaskWeek):
def requires(self):
return [self.ArtistStreamDay(d1) for d1 in self.days_in_week]
def output(self):
return TargetUtils.hdfs("/data/artist_streams_%s.tsv" % self.date_str
def run(self):
artist_count = defaultdict(int)
for file1 in self.input():
for line2 in TargetUtils.line_read(file1):
timestamp, artist, track = line.strip().split()
artist_count[artist] += 1
with self.output().open('w') as out_file:
for artist, count in artist_count.iteritems():
print >> out_file, artist, count
Optimizition notes:
date_value property, and converted
into Arrow data type.date_str is transformed from date_value, and
converted from a function into a instance property after the first call.@luigi.ref_tasks bind ArtistStreamDay as AggregateArtistsWeek's
instance property, so we can use self.ArtistStreamDay(d1) form to
instantiate some task instances.TaskWeek, it'll has
self.days_in_week property automatically.TargetUtils.line_read replaced original function that needs two
lines codes to complete the feature, and return a Generator directly.artist_project/luiti_tasks/aggregate_artists_week.pyfrom luiti import *
@luigi.ref_tasks("ArtistStreamDay')
class AggregateArtistsWeek(TaskWeekHadoop):
def requires(self):
return [self.ArtistStreamDay(d1) for d1 in self.days_in_week]
def output(self):
return TargetUtils.hdfs("/data/weeks/artist_streams_%s.tsv" % self.date_str
def mapper(self, line1):
timestamp, artist, track = line.strip().split()
yield artist, 1
def reducer(self, artist, counts):
yield artist, len(counts)
Yes, it's almost no difference to luigi, except the self.days_in_week
property and @luigi.ref_tasks decorator.
pip install luiti
Or lastest source code
git clone https://github.com/luiti/luiti.git
cd luiti
python setup.py install
The time library is Arrow , every Task
instance's date_value property is a arrow.Arrow type.
luiti will convert date paramters into local time zone automatically. If
you want to customize time, please prefer to use
ArrowParameter.get(*strs) and ArrowParameter.now() to make sure you
use the local time zone.
We highly recommend you to use cached_property, like
werkzeug said, "A decorator that
converts a function into a lazy property. The function wrapped is called
the first time to retrieve the result and then that calculated result is
used the next time you access the value".
This function is heavily used in 17zuoye everyday, we use it to cache lots of things, such as a big data dict.
class AnotherBussinessDay(TaskDayHadoop):
def requires(self):
return [task1, task2, ...]
def mapper(self, line1):
k1, v1 = process(line1)
yield k1, v1
def reducer(self, k1, vs1):
for v1 in vs1:
v2 = func2(v1, self.another_dict)
yield k1, v2
@cached_property
def another_dict(self):
# lots of cpu/io
return big_dict
cached_property.# 1. Bind related tasks lazily, and can be used as instance property directly.
@luigi.ref_tasks(*tasks)
# 2. Support multiple file output in MapReduce
@luigi.multiple_text_files()
# 3. Run MapReduce in local mode by only add one decorator.
@luigi.mr_local()
# 4. Check current task' data source's date range is satisfied.
@luigi.check_date_range()
# 5. Check current task can be runned in current date range.
@luigi.check_runtime_range(hour_num=[4,5,6], weekday_num=[1])
# 6. Let Task Templates under [luigi.contrib](https://github.com/spotify/luigi/tree/master/luigi/contrib) to follow with Luiti's Task convertion.
@luigi.as_a_luiti_task()
class AnotherBussinessDay(TaskDayHadoop):
pass
When executing a MR job, luigi will write result to a file with timestamp instantly. If the task successes, then rename to the name that the task's original output file path. If the task fails, then YARN will delete the temporary file automatically.
for line1 in TargetUtils.line_read(hdfs1), line1 is an
unicode type.for json1 in TargetUtils.json_read(hdfs1), json1 is
a valid Python object.for k1, v1 in TargetUtils.mr_read(hdfs1), k1
is an unicode type, and v1 is a Python object.We recommend to use TargetUtils.hdfs(path1). This function compacts
the MR file result data format that consists of "part-00000" file blocks.
mrtest_input and mrtest_output,
these mimic the MapReduce processing.@MrTestCase to decorator your test class,
and add your task class to mr_task_names list.mrtest_attrs to mimic properties
that generated in production mode.buy_fruit_day.py
from luiti import *
class BuyFruitDay(TaskDayHadoop):
def requries(self):
...
def output(self):
...
def mapper(self, line):
...
yield uid, fruit
def reducer(self, uid, fruits):
price = sum([self.price_dict[fruit] for fruit in fruits])
yield "", MRUtils.str_dump({"uid": uid, "price": price})
@cache_property
def price_dict(self):
result = dict()
for json1 in TargetUtils.json_read(a_fruit_price_list_file):
result[json1["name"]] = json1["price"]
return result
def mrtest_input(self):
return """
{"uid": 3, "fruit": "Apple"}
{"uid": 3, "fruit": "Apple"}
{"uid": 3, "fruit": "Banana"}
"""
def mrtest_output(self):
return """
{"uid": 3, "price": 7}
"""
def mrtest_attrs(self):
return {
"price_dict": {
"Apple": 3,
"Banana": 1,
}
}
test file
from luiti import MrTestCase
@MrTestCase
class TestMapReduce(unittest.TestCase):
mr_task_names = [
'ClassEnglishAllExamWeek',
...
]
if __name__ == '__main__':
unittest.main()
Using TaskBase's builtin extend class function to extend or overwrite
the default properties or functions, for example:
TaskWeek.extend({
'property_1' : lambda self: "property_2",
})
extend class function compacts with function, property, cached_property,
or any other attributes at the same time。When you want to overwrite
property and cached_property, you just need a function value, and
extend will automatically converted into property and
cached_property type.
Q: How atomic file is supported?
A: As luigi's document mentioned that "Simple class that writes to a temp file and moves it on close()
Also cleans up the temp file if close is not invoked", so use the self.input().open("r") or
self.output().open("w") instead of open("some_file", "w").
Q: Can luigi detect the interdependent tasks?
A: It's not question inside of luigi, but it's a question about topological sorting
as a general computer science topic. The task scheduler is implemented at luigi/scheduler.py .
Q: How to pass more parameters into luiti tasks?
A: You can create a key-value dict, date_value is the key, and your
customize parameters are the values.
If you have other unresolved questions, please feel free to ask questions at issues.
nosetests
# or
nosetests --with-coverage --cover-inclusive --cover-package=luiti
tox -e py27-cdh
Please let us know if your company wants to be featured on this list!
MIT.