An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.
An offline task management framework, built on top of luigi.
Author and Maintainer @mvj3 , feel free to contact me :)
© 2015. All rights reserved.

1, 大家好,我下面讲如何用 Luiti 来构建数据仓库。讲之前我先简单自我介绍一下,我叫陈大伟,之前在一家教育互联网公司里做数据工程师。日常工作包括建设分层的数据仓库,教育模型的数据,BI 报表等。 用到的主要技术是 Hadoop + Python ,并且 Luiti 也正是在这一实践中生长出来。在这里也向大家推荐一种提高自己代码质量的技巧,那就是坚持"业务代码和开源代码的双线开发模式”,其中的开源代码即是可以剥离出来的与商业机密无关的代码库或者框架,我坚持到现在已经三年了,我做了一个可视化的时间轴 http://mvj3.com/projects/ 。右下角是我的联系方式,我的个人网站是 mvj3.com ,Github 等互联网账号一般都是 @mvj3 ,左下角是 Luiti 的 Github 组织地址,欢迎关注和参与。

2, Luiti 是构建于 Luigi 之上的,其实 Luigi 就是大家熟悉的马里奥的二弟。左边的就是红色的马里奥,又矮又胖,但是能干大事,其实就是那个笨重的 Hadoop 。右边这幅图里有一个绿色的 Luigi ,Python 社区不是有句名言吗,“人生苦短,必须苗条”,我用 Python 也就是这个目的,比直接写 Java 效率高多了。Luigi 是在一家比较大型的创业公司诞生的,提供流媒体音乐服务,叫 Spotify,总部在瑞典首都斯德哥尔摩,但 Luigi 主要是由他们在纽约的数据团队构建的。
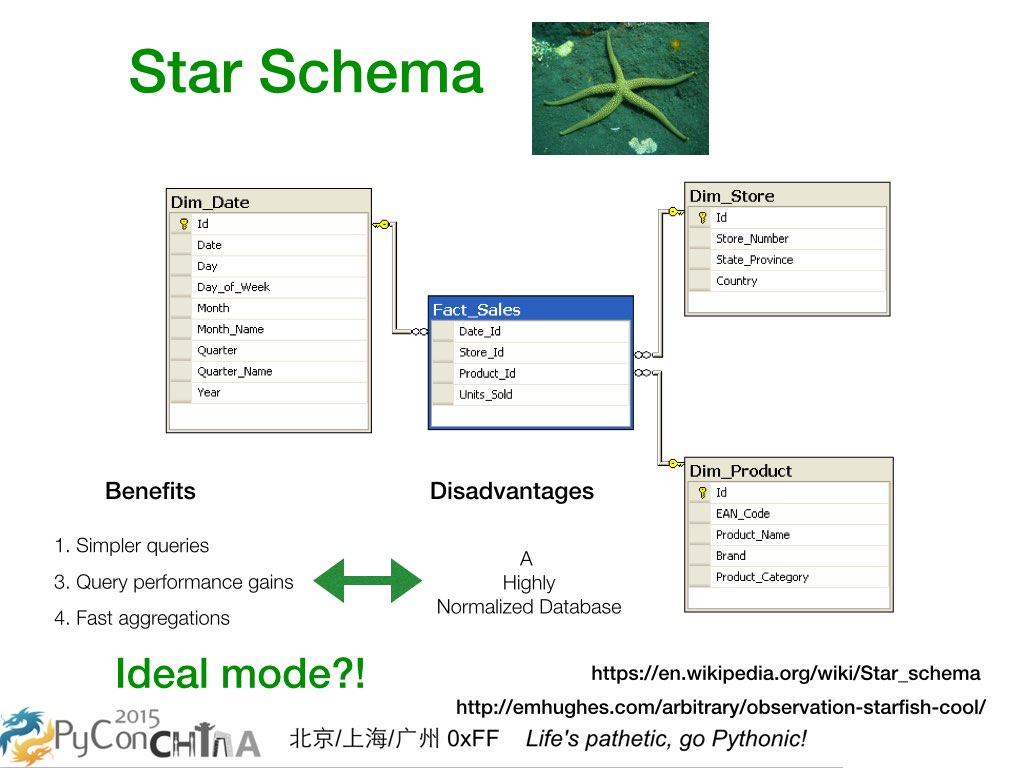
3, 现在我们来看数据仓库里的基本设计模式,也就是星型模式。大家可以看看右上角绿色的海星,就知道星型模式是从一个中心出发,发射出好几个维度。大家在中间看到的数据库设计是从维基百科上拷贝过来的,内容是和销售管理有关。最中间蓝色的是销售的事实表,外面三个灰色的是维度表。事实表有日期,商店,产品,和卖出单元数量等信息,三个维度表分别是按日期统计,按商店统计,按产品统计。非常一目了然的设计。因为独立出了表,加了维度索引后,所以访问性能会很高。因为设计模块化,所以很容易和其他数据集成。坏处也是有的,就是这是一个高度范式化的设计,不容易更改表结构设计。这是一个理想的模型吗?我们接下来看看 Luiti 在工程上如何让我们可以完全弥补这种缺陷。
 4,
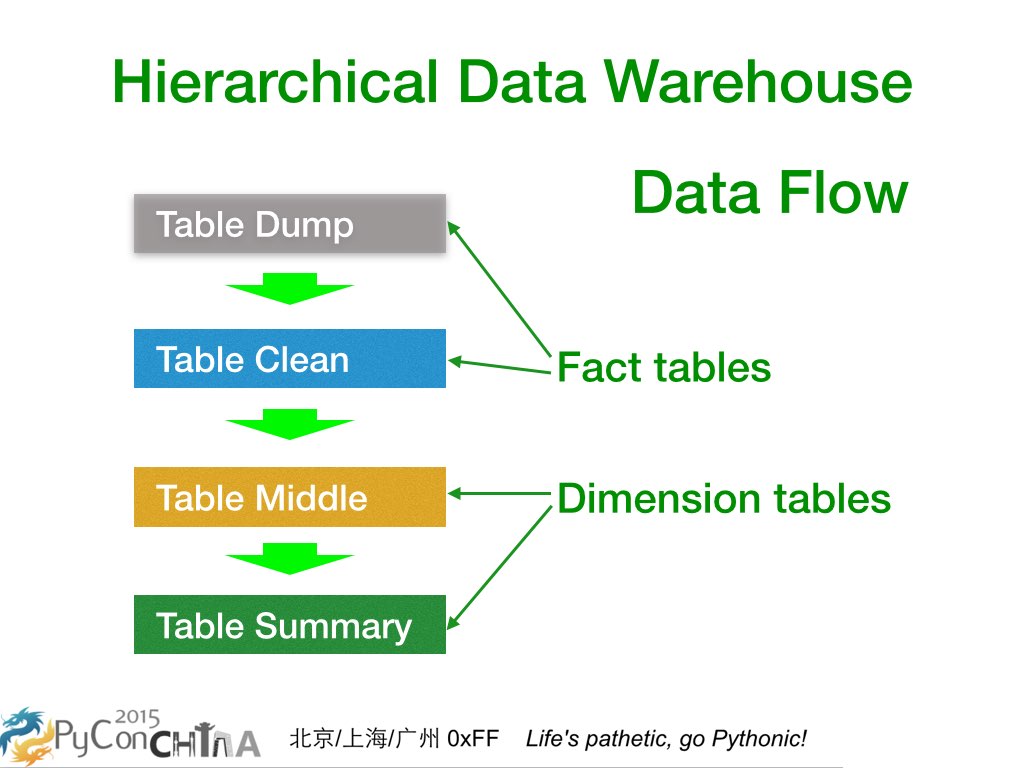
这是我之前所处团队里设计的层级化数据仓库。上面两个是 Table Dump 和 Table
Clean ,属于事实表;下面两个是 Table Middle 和 Table Summary
,属于维度表。正好对应了刚才的说的星型模式,还有这里面每一个都可以含有不止一个 Luiti
Package。大家也可以从上往下看到,这在事实上也构成了数据流。只要最上面的数据,即
Table Dump,以日志或快照形式保持不变,下面的数据全都是可以通过一定的业务逻辑转化得到。如果业务发生变化, 那么建另外的 Luiti Package 处理就好了,有些公用的业务逻辑处理代码也是可以继续沿用的。
4,
这是我之前所处团队里设计的层级化数据仓库。上面两个是 Table Dump 和 Table
Clean ,属于事实表;下面两个是 Table Middle 和 Table Summary
,属于维度表。正好对应了刚才的说的星型模式,还有这里面每一个都可以含有不止一个 Luiti
Package。大家也可以从上往下看到,这在事实上也构成了数据流。只要最上面的数据,即
Table Dump,以日志或快照形式保持不变,下面的数据全都是可以通过一定的业务逻辑转化得到。如果业务发生变化, 那么建另外的 Luiti Package 处理就好了,有些公用的业务逻辑处理代码也是可以继续沿用的。
 5,
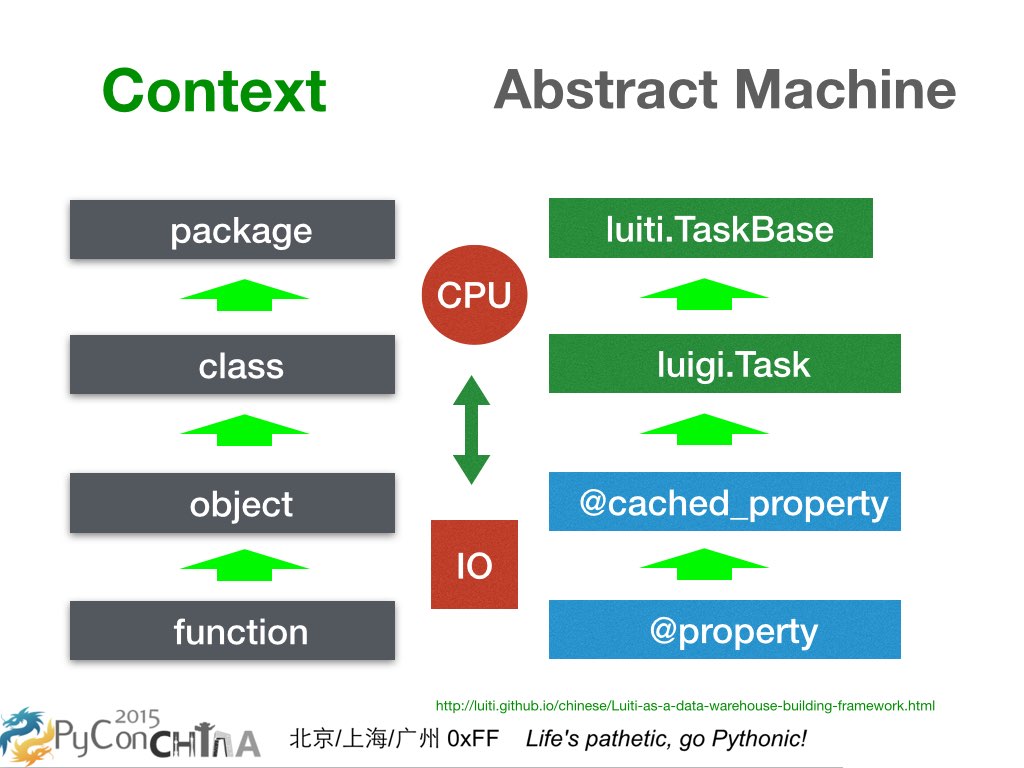
在涉及团队协作的时候,大家共同遵守一个框架是必然的。这幅图非常有意思,左边讲的是上下文,从底向上依次是
function, object, class, package;右边讲的是计算模型的抽象,是关于左边的具体实现,从底向上依次是
@property ,@cached_property,luigi.Task,luiti.TaskBase 。大家可以看到,Luigi 位于一个 Module 的层面,Luiti
位于一个框架的层面。具体这里我就不展开讲了,我已经写在 《使用 Luiti 来构建数据仓库》系列文章 的其中一篇《Luiti 在数据仓库开发程序中的位置》了,感兴趣的可以去看看。
5,
在涉及团队协作的时候,大家共同遵守一个框架是必然的。这幅图非常有意思,左边讲的是上下文,从底向上依次是
function, object, class, package;右边讲的是计算模型的抽象,是关于左边的具体实现,从底向上依次是
@property ,@cached_property,luigi.Task,luiti.TaskBase 。大家可以看到,Luigi 位于一个 Module 的层面,Luiti
位于一个框架的层面。具体这里我就不展开讲了,我已经写在 《使用 Luiti 来构建数据仓库》系列文章 的其中一篇《Luiti 在数据仓库开发程序中的位置》了,感兴趣的可以去看看。
http://luiti.github.io/chinese/Luiti-as-a-data-warehouse-building-framework.html
 6,
现在先给大家展示 Luiti Demo。
6,
现在先给大家展示 Luiti Demo。
在本地启动测试的可视化,http://localhost:8082/luiti/dag_visualiser
这就是 Luiti 任务可视化的后台,我们通过它来完成任务 元数据 的管理和导航。右上角是参数查询,右边上面是当前选择用于展示的 Luiti Package,下面则是归属于上面 Package 里的各个 Task 任务,这里也会通过添加后缀来标示是从属于哪个 luiti package ,点击它们,我们在左边就可以看到我们刚才选择的那个任务的详情。
最上面一行是任务及其参数,第二行是当前任务的数据输出地址,是可以配成一个分布式文件存储的 Web 地址的。第三行是源代码,可以点击打开。
第四行是这个 Task 类的文档。再下面四个就是当前任务和其他任务的关系。 为了认识这个关系,我们先可以来看下面的拓扑图,初步可以看到有七个节点,节点之间被有方向的边连接起来。这个就是有向无环图,一般被简称为 DAG 。
这是一个网站用户行为统计的例子, 第一步我们得到 DumpWebLogDay ,即用户访问日志,还有 DumpBrowserMapDay,可以把浏览器名称编码为整数。 第二步我们清洗 DumpWebLogDay ,得到 CleanWebLogDay ,即干净合法的用户访问日志。 第三步我们构建出三个中间表,分别是按地区统计,按浏览器统计,汇总统计。值得注意的一点是汇总统计是直接从浏览器统计而来的,这样计算量大大减少。 第四步我们最终得到了完整的用户访问统计报表。
通过刚才这个说法,我们就可以想象一个大型的数据仓库,最下面有很多输入数据的任务,再经过一层层转化,再把数据输出去,那这就是一个非常复杂的拓扑图。如果你抓住其中一个节点,那它就有几个输入数据的任务,这些输入数据的任务也可能有再下面的输入数据的任务。同样,这个节点也会输出数据给上面,而上面也会继续输出数据给上面。
对应到我们这四行,就是有这个任务直接依赖的,和间接依赖的,也有别的任务直接依赖它的,和别的任务间接依赖它的。
大家可能会有点好奇这些可视化数据是如何计算出来的,其实很简单,就是直接把代码跑起来,取出任务之间的依赖关系,就可以了。占用内存量一点也不高,几十兆足以,因为这里的信息只关注任务的管理,而不是具体业务的内部细节数据。
 7,
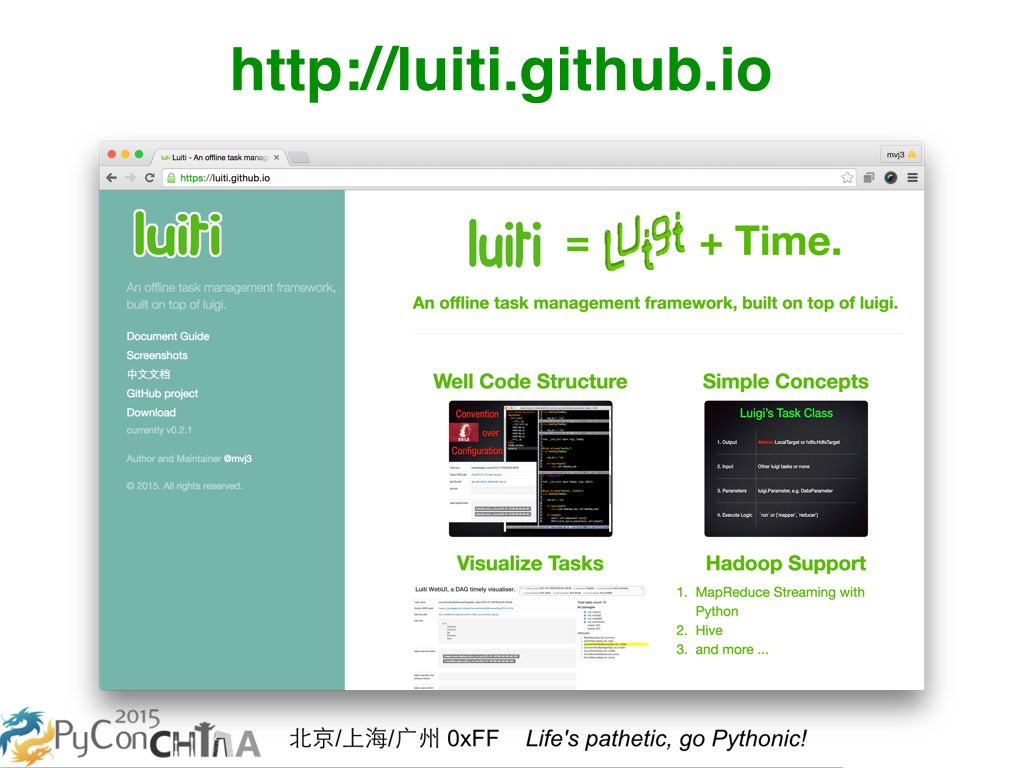
最近我已经给 Luiti 做了官方网站。Luiti 是一个生造的单词,是把 Luigi 和 Time 两个单词组合起来。Luiti 也是一个离线任务管理框架,构建于 Luigi 之上。用 Luiti 来构建数据仓库的好处是,
7,
最近我已经给 Luiti 做了官方网站。Luiti 是一个生造的单词,是把 Luigi 和 Time 两个单词组合起来。Luiti 也是一个离线任务管理框架,构建于 Luigi 之上。用 Luiti 来构建数据仓库的好处是,
第一点,良好的代码结构。Luiti 对文件目录命名已经做了强制的约定,也是遵循了业界流行的“约定大于配置”这一理念。也鼓励用户尽量把一个大工程拆成一个一个小项目,Luiti 也是直接复用了 Python 社区里官方默认的软件包规范的。 第二点,简约的核心概念。对于数据仓库来说,其设定就是采用离线和异步的程序任务来管理和生产数据,因此有必要抽象出 Task 概念,即原子性的输出和输入,运行逻辑,以及可变参数。执行逻辑可以就是 Python 代码,或者包装 Hive SQL 等外部命令,总之在 Python 这个动态语言里是很灵活的。 第三点,任务的可视化。基于刚才说良好的代码结构和简约的核心概念,我们很容易把基于 Luiti 框架构建的 若干个 Python Package 代码作为数据去动态的运行和分析,并通过网页呈现出来。 第四点,Hadoop 支持。毋庸置疑,在当前,构建数据仓库根本就离不开 Hadoop 或者其他的大数据技术。我们可以用 Python 写 MapReduce Streaming,也可以写 Hive SQL ,还有其他几十个模版,常用的都有了,这些全都是由 Luigi 来提供的。
8, 任何相关问题都可以提!